Improving the performance of GDBack using Go channels
Table of Contents
The first time I did something with Golang was out of sheer necessity. I was using Goflow2 as a Netflow collector. Goflow2 could not produce timestamps in milliseconds as they are described in the Netflow standard, so I contributed to the code to add these parameters. Since then, I’ve wanted to do something with Golang, but I’ve never had the time. To learn practically, I decided to take a look at my colleague Ivan Santos’ project; GDBack, a tool for quickly extracting file information from a disk or a folder. In this post, I share a brief comparative analysis that I conducted between the code of GDBack and a possible improvement.
Previous approach of GDBack #
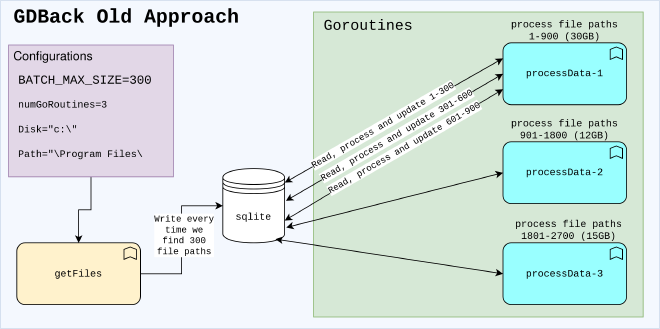
A brief explanation of the logic #
The logic can be explained simply in the following points:
- Several checks are performed, such as verifying that the program is running on Windows and with administrator privileges.
- Several questions are asked to choose the disk, the number of Goroutines to use, and the folder (in case the entire disk doesn’t need to be analyzed).
- All the files on the disk are recursively traversed using the
filepath.Walkfunction. Later, we realized that thefilepath.WalkDirfunction is significantly faster. For each file:- It is checked that it’s not a directory.
- A struct is created containing various data, with only the
FullPathfield being filled. - The struct is added to a list.
- When the list exceeds BATCH_MAX_SIZE (300 file paths by default), it is inserted into an SQLite file.
- N Goroutines are created, each one:
- Chooses equal sections of the total number of file paths. For example, if there are 9000 files and 3 Goroutines, the first Goroutine analyzes files 1 to 3000, the second one analyzes files 3001 to 6000, and the third one analyzes files 6001 to 9000.
- Each Goroutine iterates over the range of file paths, reading BATCH_MAX_SIZE from the database, calculating information related to the files, and updating the data with that information.
Possible drawbacks #
Writing and reading from the database #
The program writes to the database for the first time when traversing the files. Later, it reads from the database and updates the entries in it. The size of BATCH_MAX_SIZE directly influences the number of operations performed on the database. For very small sizes, a more significant number of writes are performed. For a larger size of BATCH_MAX_SIZE, fewer writes are performed, but more memory is consumed.
Unbalanced workload among the Goroutines #
The separation of work is based on the number of file paths. All Goroutines contain the same number of file paths, but the size of those files can be different. Since there are operations that can be expensive, such as calculating the file hash, if Goroutine B receives files with a total size twice that of Goroutine A, Goroutine A will finish earlier while Goroutine B continues working.
The following diagram describes the code’s operation and the described problems:
The new approach of GDBack #
A brief explanation of the logic #
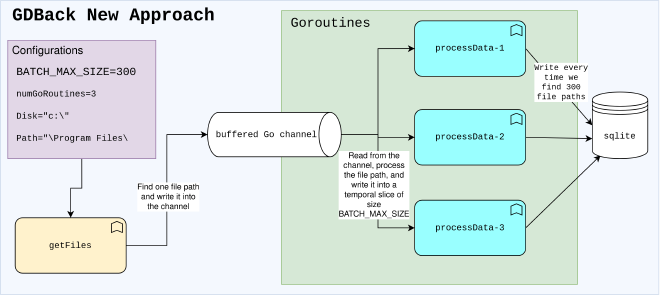
This approach aims to solve the problems with the previous logic by reducing the number of operations in the database and balancing the workload properly among the workers.
The logic is as follows:
- Create a buffered channel of size MAX_FILEPATH_CHANN.
- Create N Goroutines that read from that channel.
- Iterate over the disk and send all file paths to the channel.
- Since the Goroutines are ready, they can start working as soon as the first file path is written This allows the search for file paths and the processing of the files to be concurrent. It also ensures that the workload is balanced among the different Goroutines. In addition, the data was written to the database, read from it, and updated, now, the data will only be written once every MAX_BATCH_SIZE, reducing significantly the number of operations.
Possible problems and limitations #
Size of the channel #
The function that finds files is considerably faster than the Goroutines that process the files. File paths will be written to the channel faster than the Goroutines can process them, causing the buffer to fill up. If the buffer is not large enough, the getFiles function will fill the buffer and block until the Goroutines process events from the channel. This won’t actually reduce the processing time of a tool since it will be limited by the processing rate of the workers, not getFiles. However, the sooner the getFiles function finishes, the sooner we will know the number of files to analyze, and the sooner we can provide the user with an estimated time. This estimation can be provided faster by increasing the size of the channel buffer, which comes at the cost of higher memory usage.
The following diagram describes the code’s operation:
Testing results #
Hypothesis #
To compare results, measurements are taken in several functions of the code:
- Previous logic:
getFiles: Look for files and write the file path into a struct and into the databaseprocessData: Go routines that read from the database and process the files
- Improvement:
SendFilePaths2Channel: Look for files and write the file path into the channeldataProcessor: Go routines that read from the channel and process the files
In processData and dataProcessor we are taking elapsed time every BATCH_MAX_SIZE (300 events).
Logic suggests that SendFilePaths2Channel will be faster than getFiles since it doesn’t generate any struct or write to the database; it simply reads the filename and sends it through the channel.
On the other hand, dataProcessor should also be faster since it doesn’t perform database reads and updates. Instead, it continuously reads from the channel and writes every BATCH_MAX_SIZE. Additionally, the set of workers should finish faster since the workload is more evenly distributed.
Results #
Both scripts are executed to analyze the folder \Program Files\. The results are favorable for the new method.
|
|
|
|
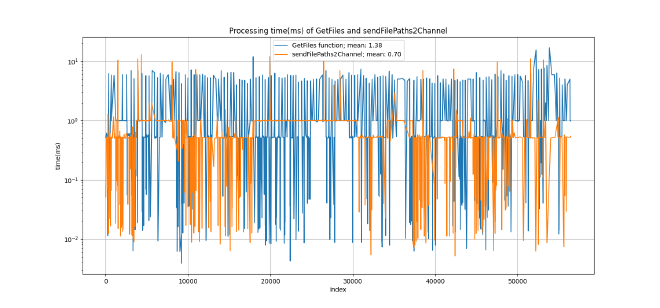
We can observe that for 48151 files, there is a considerable improvement of 5.81 seconds, a decrease of 35.29%, which can be quite significant for the analysis of large quantities of files. Figure 1 presents a comparison between the getFiles and sendFilePaths2Channel functions, in which the files with 0 processing time are excluded. These files are neither written to the database nor sent through the channel as they refer to reading errors or directories. On average, it takes 0.68 milliseconds less to enqueue file paths (new method) compared to writing it into the database (old method).
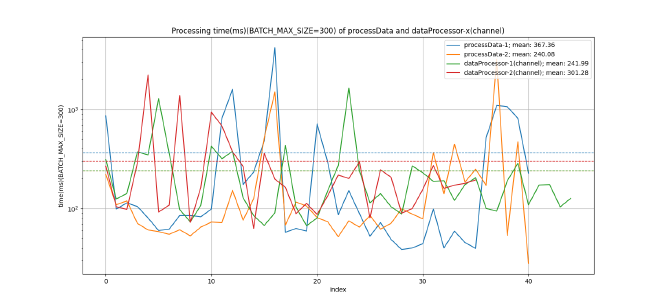
Furthermore, in Figure 2, an improvement in the processing time of each file is also observed. By summing the times of both Goroutines, we achieve 607.44 milliseconds with the first method and 543.27 milliseconds with the second method.
Effects of directory and I/O caches on GDBack #
There was something that confused me for a while. My computer has Ubuntu 22.04.1 LTS installed, and to test the programs, I was compiling with the options GOOS=windows GOARCH=amd64 to later run the tool on a Windows 10 virtual machine. The thing is, sometimes the tool with the old logic was faster than the new one, which, from my perspective, didn’t make any sense. After testing on several machines with Windows 10 installed as the host, I realized that it was the first-run execution
of the tool that was faster. The following results show the difference in speed between running the tool with the new logic for the first time and the second time.
|
|
|
|
In fact, the following figures show a significant difference between the speed of the first execution and the second, especially in the processing time of the files rather than the queuing time of the file paths. There is a decrease of 85,9402%.
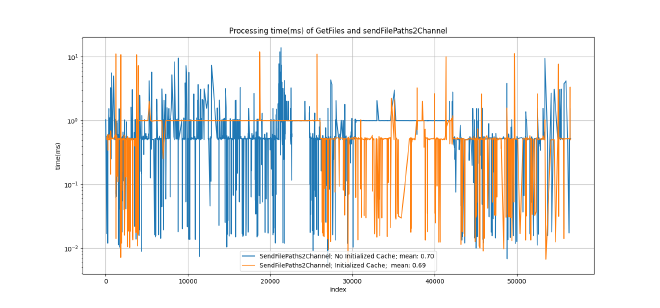
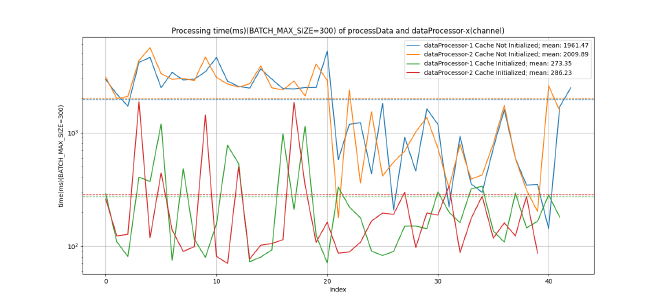
The processing time decreases considerably due to the initialization of the directory and I/O caches, which are initialised after the first run, making the second run significantly faster. In applications such as this, which will not be executed multiple times but rather only once, it can be useful to clear the cache before execution. To clear the cache on Linux operating systems and execute an application you can use the following command:
sync; echo 3 | sudo tee /proc/sys/vm/drop_caches && ./yourapp
Conclusion #
Using Go channels is a very effective way to distribute the workload amongst Goroutines, and in this case, it also reduces interactions with the database, making the tool even more efficient.